A gentle introduction to event cameras
Introduction
Can computer see like we humans do? Computer vision is a joint branch of machine learning, statistics, and computer science. It’s main goal is providing artificial agents (e.g., robots, autonomous cars, drones, surveilling systems) the ability to see and understand the environment. Deep learning and machine learning are contributing enormeously to computer vision. Open-source implementations of the recent literature (e.g., torchvision, tensorflow, recently opencv) demonstrate that deep learning applications are mature and ready for industrial applications (#TODO: add examples). The Figure below is an (abused) example of how fast the community has grown during the past decade. Today, artificial agent perform better than human on huge set of classes.

Old joke (link https://xkcd.com/1425/)
Is it all? Has computer vision reached complete maturity? I believe it’s not.
Standard cameras suffer of major intrinsics issues which can hardly be solved - high bandwidth, high power consumption, low dynamic range. Humans don’t see images at fixed frame rates. We process only the changes of our sourrindings, avoiding to process again and again the statical part of the scene. Our approach is faster and more efficient, as we don’t process the same information multiple times.
I praise the human vision system because Nature has always been a source of inspiration for engineering. Could we rethink computer vision, taking source from Nature?g Event-cameras (cameras based on events) could be the answer. In the following paragraphs, I try to convince the reader of the potentials of event-based vision applications. This article is structure as follows. I present event-cameras, their principle of operations, and their motivation. Next, I show some solutions to solve the main challenges of event-based vision. And finally, I conclude with a what I believe its the key: everyone can contribute.
Event-cameras
Traditional cameras collect light and, at fixed frame-rate, output a single frame. This approach suffers, however, of severe limitations. If part of the scene is static, each frame contains the same pixel information, and the data becomes redundant. Consequently, standard cameras with high frame-rate produce a prohibitive large amount of throughput—most of which redundant if no change occurs—that no algorithm can efficiently process. These limitation leads to other common issues in standard computer vision: narrowed dynamic range and blooming.

GoPro vs Prophesee event-camera
Each standard image is digitalized and stored with a finite range of values (e.g., 256 values per channel). If the light varies abruptly in the scene, the digitalization process loses much of the information to fit into the fixed range. Consequently, traditional cameras have a narrow dynamic range, especially in automotive applications. For example, the sun in front of the driver is a problematic issue for a standard camera. Moreover, if the incoming light is too much, as in the after-mentioned example, the pixels saturate and the resulting image is burned.
The amateur photographer is aware of these issues and can use these characteristics to create more artistic photo. On the other hand, computer vision algorithms must be reliable, not artistic, and their reliability is under attack in dynamic scenarios or when sources of lights are present in the scene.

This is me saying "hello" at an event-camera
Can we rethink computer vision?
This question lead us to the central idea of event-cameras and its paradigm. Event-cameras capture change of intensities (also called events) in an asynchronous manner. *Each event has 4 values: the position tuple on the image plane (x, y), the polarity of the change (positive or negative), and the timestamp of the its occurrence*. This paradigm shift leads to some interesting advantages.
First of all, since each pixel work independently, event-cameras are more robust against strong light changes. When the pixel of a standard camera receives too much light intensity (e.g., if a camera is mounted on a car heading west at dawn), it “flows” into the neighborhood pixels (blooming effect). On the other hand, pixels of event-cameras don’t store intensity values: events are spiked immediately when a threshold is reached. No blooming happens, and dynamic range is extremely high (140 dB vs 60 dB of traditional cameras). As you can imagine, if each pixel transmit only the intensity changes, the bandwidth—the amount of transmitted data—stays very low, while the rate—the speed of data transmission—grows over 1 million events per second. Consequently, events paradigm is for vision what oil is for energy: efficient, rapid, and flexible. In the following Figure from (Gallego et al. 2020) you can find an example of what I’m saying.
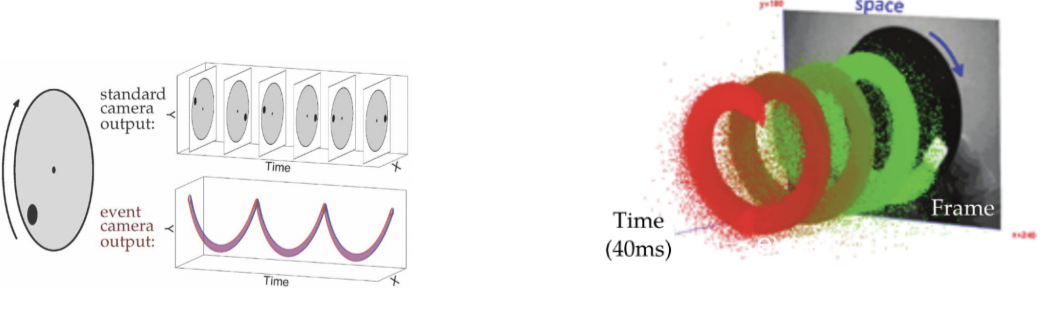
Events vs frames
These interesting characteristics made event-cameras the best available solution for robotics platform, intrusion detection, and fast movement tracking. Events data preserve privacy of the monitored space as well, because no subjects' details (e.g., face, eyes, and so on) are captured. Major companies 1 are exploring low-cost event-based applications for intrusion detection.
Where do the disadvantages lay?
Event-cameras detect only the movements and transmit asynchronous data. If the scene is static, like in a beautiful mountain panorama, the only events are noise. This new way of imaging makes events data incompatible with existing computer vision applications. Moreover, deep learning models rely on synchronous tensor representation, therefore even the deep learning revolution is not directly available for event cameras.
Solutions
If you were looking for the Saint Grail of computer vision, look somewhere else. They are not. Event-cameras are novel, expensive sensors—especially if you are a first-time practitionares in computer vision. A huge effort is still required to unlock their potential. I want to send this message clearly: everyone can participate. Research in computer vision—and in many other fields of compute science—needs fresh ideas. What makes event-cameras hard to employ also makes them exciting—we are explorer looking for new, more efficient paths.
What do we need?
We need data. How could we exploit event-cameras otherwise? Dataset collection is boring and hard, but necessary. There are other, more interesting paths worth noting. For example, domain adaptation could be worth some consideration. We could train on simulated dataset; if it doesn’t work in simulation, it doesn’t work in the real world real. Simulation could be a game changer in event-based vision; we need standardize, easy-to-use simulators. They must be open-source as everyone could contribute.
Scaramuzza and his team developed an open-source simulator (Rebecq, Gehrig, and Scaramuzza 2018). This could be exploit to generate huge amount of publicly available dataset, both with complete simulation or by converting standard computer vision dataset to events data. They made their point in an elegant way: they engineered an approach for reconstructing gray-scale images from events (Rebecq et al. 2019). Their reconstruction is smooth and clear even in impossible conditions—e.g., capturing a bullet moving at 1,000 km/h as in the following Figure. This should be clear by now: they could only achieve this amazing reconstruction quality using simulated data for training.

Triple-shot dwarf (P10 camera, event-camera, and with a real gun)
We can group events together and use events as standard frames. Events frames can be stacked in tensors and used as input for synchronous deep learning models (e.g., CNN, ANN). Currently, representing events as frames is the most common technique to exploit event-cameras. This approach increases, however, bandwidth and redundancy, and its benefits are limited compared to standard cameras. Asynchronous machine learning models—e.g., Spiking Neural Network—and sparse CNN (Messikommer et al., n.d.) are fascinating path of research.
Conclusion
I presented event-cameras and showed their advantages and their limits. I discuss how and in what measures event-cameras could change computer vision applications. In particular, I focused on application that necessitates low bandwidth, high acquisition rates, and low power consumption. The range of applications of event-camera is a broad one: from space applications, in which low energy consumption is the key to pack lighter batteries and ultimately save millions on budget, to autonomous driving, where blurring and overflowing are still dangerous for the driver. The path toward exploiting event-based cameras is clear. Realistic and easy-to-use simulators could save time and energy in collecting data. A well-engineered event-based vision package, lets call it OpenEV, would certaintly increase the interest of industries and practitionares, especially if big players were backing the project (we’ll see, Samsung and Sony have already shown their interest). If I made you more curious, kudos to me! I refer you to (Gallego et al. 2020) —a fantastic and exhaustive overview of event-cameras overview—and to Davide Scaramuzza’s tutorial on event-cameras.
Bibliography
Gallego, Guillermo, Tobi Delbruck, Garrick Michael Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, et al. 2020. “Event-Based Vision: A Survey.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Institute of Electrical and Electronics Engineers (IEEE), 1. http://dx.doi.org/10.1109/TPAMI.2020.3008413.
Messikommer, Nico, Daniel Gehrig, Antonio Loquercio, and Davide Scaramuzza. n.d. “Event-Based Asynchronous Sparse Convolutional Networks.” https://youtu.be/LauQ6LWTkxM?t=4.
Rebecq, Henri, Daniel Gehrig, and Davide Scaramuzza. 2018. “ESIM: An Open Event Camera Simulator.” https://www.blender.org/.
Rebecq, Henri, René Ranftl, Vladlen Koltun, and Davide Scaramuzza. 2019. “High Speed and High Dynamic Range Video with an Event Camera.” IEEE Trans. Pattern Anal. Mach. Intell. (T-PAMI). http://rpg.ifi.uzh.ch/docs/TPAMI19%5FRebecq.pdf.